
Het moment waarop een Drupal-site uitvalt, is zelden technisch complex maar vrijwel altijd organisatorisch chaotisch, bijvoorbeeld net na een deployment of tijdens piekverkeer. Er komt een melding binnen, iemand ziet een witte pagina of een 500-fout, en binnen een paar minuten ontstaat er druk. Intern, extern, soms richting klanten. En dan gebeurt er iets interessants: iedereen wil iets doen. Wat je in de eerste 30 minuten doet, bepaalt vaak of een incident klein blijft of juist uit de hand loopt.

Wat er meestal gebeurt (en waarom dat misgaat)
In de praktijk zie je een vrij vast patroon. Iemand logt in, probeert iets te fixen, wist caches, zet modules aan of uit, of voert “even snel” een update uit. Soms wordt er zelfs direct in productie getest.
Dat gebeurt niet omdat mensen het niet snappen, maar omdat de druk oploopt.
Het probleem is dat deze reflexen het vaak juist erger maken. Zeker bij Drupal, waar veel afhankelijkheden samenkomen: PHP-versies, Composer-packages, modules, database-structuur en caching-lagen.
Je kan bijvoorbeeld een cache legen terwijl de echte oorzaak in een mislukte deployment zit. Of een module uitschakelen die juist nodig is voor de database consistency. Dan ben je niet aan het oplossen, maar aan het verschuiven.
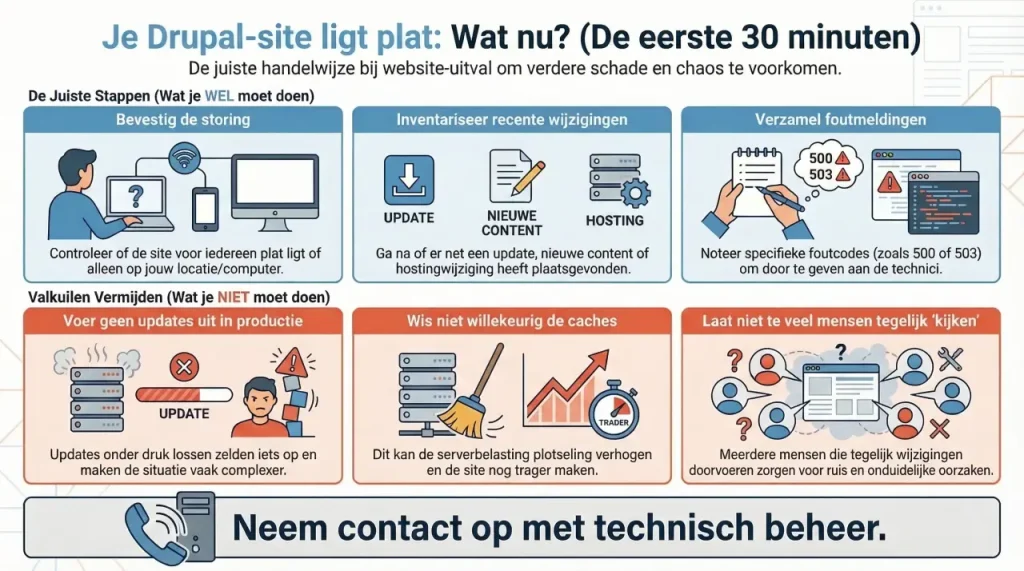
De eerste 30 minuten draaien niet om repareren, maar om stabiliseren en begrijpen. Je wil eerst weten wat er nou echt gebeurt.
Key takeaways
- De eerste 30 minuten draaien niet om repareren, maar om stabiliseren en begrijpen.
- Controleer eerst of het een echte, globale storing is voordat je ingrijpt.
- Zoek de oorzaak vaak buiten Drupal, bijvoorbeeld in server, PHP of resources.
- Raak productie zo min mogelijk aan zonder volledig beeld; voorkom dat je informatie verliest.
- Werk volgens een vaste volgorde: bevestigen, afbakenen, analyseren en pas daarna ingrijpen.
Stap 1: bevestig dat het probleem echt bestaat
Dit klinkt simpel, maar wordt verrassend vaak overgeslagen.
Eén melding betekent nog niet dat je hele site down is. Je kan bijvoorbeeld een specifieke route hebben die stuk is, terwijl de rest nog werkt. Controleer:
- Is de site volledig onbereikbaar of alleen een specifieke pagina?
- Zie je een HTTP-statuscode zoals 500, 502 of 503?
- Werkt de site op mobiel of via een andere verbinding wel?
Gebruik bij voorkeur externe checks, zoals een uptime-monitor (bijv. UptimeRobot) of een eenvoudige HTTP-check via curl (bijv. curl -I https://jouwdomein.nl). Daarmee sluit je client- en cachingproblemen uit.
Je wil hier één ding scherp krijgen: hebben we een echte storing, of kijken we naar iets lokaals?
Stap 2: kijk eerst buiten Drupal
Wat je vaak ziet: iedereen duikt meteen Drupal in. Terwijl het probleem daar helemaal niet zit. Veel storingen ontstaan in de lagen eromheen:
- Webserver (Apache of Nginx)
- PHP-FPM processen die vastlopen
- Databaseconnecties die falen
- Disk space die vol is
- SSL-certificaten die verlopen zijn
Je kan bijvoorbeeld een perfect werkende Drupal-site hebben, maar als je disk volloopt door logs, stopt alles. Klaar.
Een snelle check via de server (top, df -h, systemctl status php-fpm) geeft vaak al richting. Je kan bijvoorbeeld binnen twee minuten zien of processen vastlopen of resources op zijn. En dat bespaart je een hoop zoeken in Drupal zelf.
Stap 3: check recente wijzigingen
Als een site ineens uitvalt, is de kans groot dat er net iets veranderd is.
Dat kan technisch zijn, maar ook organisatorisch.
Denk aan:
- Deployment gedaan
- Updates gedraaid (core, modules, Composer)
- Hostingwijziging
- DNS-aanpassing
Wat je dan vaak ziet: de oorzaak zit niet in “Drupal”, maar in wat er net omheen is veranderd.
Je kan bijvoorbeeld een Composer update hebben gedaan die een dependency meeneemt die niet past bij je PHP-versie. Sinds Drupal 9 en 10 zie je dit vaker, omdat Composer een centrale rol speelt.
Timing is hier bijna nooit toeval.
Stap 4: raak de productieomgeving zo min mogelijk aan
Dit is de lastigste. Zeker als er intern al vragen binnenkomen en iedereen wil weten “wat er aan de hand is”. Toch geldt: alles wat je nu aanpast zonder volledig beeld, maakt het risico groter. Denk aan:
- Even een module uitzetten
- Handmatig iets in de database aanpassen
- Configuratie overschrijven
Je verliest dan informatie. En die heb je juist nodig. Je kan bijvoorbeeld een rollback doen terwijl het probleem in de code zit. Dan trek je data en code uit elkaar, en wordt het herstel alleen maar lastiger.
Alleen als je zeker weet wat je doet, bijvoorbeeld via een gecontroleerde rollback, ga je ingrijpen.
Stap 5: verzamel gerichte informatie
Pas nu ga je echt kijken wat er gebeurt.
Je kan bijvoorbeeld:
- Drupal logs bekijken (watchdog / database log)
- Server logs checken (Apache/Nginx, PHP)
- Rond het moment van uitval zoeken naar patronen
Belangrijk: kijk niet naar één foutmelding, maar naar herhaling. Tien dezelfde errors in een minuut zeggen meer dan één losse melding. Je kan bijvoorbeeld zien dat één specifieke route steeds crasht, of dat een service niet geladen wordt. Dan heb je richting. En nog steeds: je hoeft nog niets te fixen.
Stap 6: bepaal of je moet isoleren
Soms moet je ingrijpen, maar dan om schade te beperken. Denk aan:
- Tijdelijk maintenance mode
- Load beperken
- Externe koppelingen uitschakelen
Je lost het probleem hier niet mee op, maar je voorkomt dat het erger wordt. Je kan bijvoorbeeld via een reverse proxy (Varnish, CDN) nog statische content serveren terwijl je backend instabiel is. Dat geeft je ruimte.
Wat je expliciet níet moet doen
Er zijn een paar dingen die bijna altijd verkeerd uitpakken.
Updates draaien in productie is daar één van. Updates zijn geen oplossing, maar een verandering. En veranderingen onder druk gaan zelden goed. Ook willekeurig caches legen is riskant. Drupal heeft meerdere caching-lagen. Als je alles leegtrekt, gooi je de load omhoog en maak je het probleem soms erger.
En een hele belangrijke: meerdere mensen tegelijk laten “kijken”. Wat je dan krijgt is ruis. Iemand verandert iets, een ander ziet iets anders, en voor je het weet is de oorspronkelijke oorzaak weg.
Een praktijkvoorbeeld
Je kan bijvoorbeeld een site hebben die ineens 503-errors geeft. De eerste reactie: Drupal is stuk. In werkelijkheid blijken PHP-FPM processen vast te lopen door een geheugenlek in een module-update. Requests blijven binnenkomen, maar er zijn geen vrije processen meer. Caches legen of modules uitzetten helpt dan niet. De oplossing zit in het herstarten van PHP-FPM en daarna analyseren welke code het veroorzaakt.
Dit soort issues zie je steeds vaker, omdat Drupal-installaties afhankelijker zijn geworden van externe libraries en services.
Wat deze eerste 30 minuten eigenlijk zijn
Als je het terugbrengt, gaan die eerste 30 minuten niet over techniek. Ze gaan over volgorde.
Je kan bijvoorbeeld een ervaren developer hebben die onder druk toch verkeerde stappen zet. Niet omdat hij het niet weet, maar omdat hij te snel wil. De organisaties die dit goed doen, volgen consequent dezelfde lijn: eerst bevestigen, dan afbakenen, vervolgens analyseren en pas daarna ingrijpen. Geen shortcuts. Dat zie je direct terug in hersteltijd.
Tot besluit
Een stilgevallen Drupal-site is zelden het echte probleem. Het is een symptoom. Er zit altijd iets onder: een wijziging, een resource-issue, een dependency die niet meer klopt. De eerste 30 minuten bepalen of je dat snel boven tafel krijgt, of dat je het probleem groter maakt. Je kan dus beter even niets doen, dan het verkeerde doen.
Dat voelt tegen je natuur in. Maar dit is precies waar het verschil zit tussen controle en chaos.